Blog Walkthrough Video
Overview
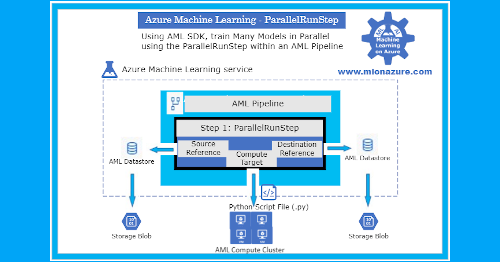
Azure Machine Learning service makes it very easy to automate the training and scoring of machine learning models using Pipelines. A Pipeline contains Steps. The newest step added is the ParallelRunStep. With the ParallelRunStep, machine learning models can be trained and scored in parallel, as depicted in figure 1, below. For an overview of pipelines, see article, MLonAzure: Azure Machine Learning Pipelines.

Model Training
A Pipeline is created and published as a PipelineEndpoint to be used for training models in parallel. The pipeline contains the ParallelRunStep as described above. This step executes the training script, which is a python script file, on each node of the Compute Cluster. Each node of the cluster takes a file when using FileDataset or a portion of the file when using TabularDataset from the input dataset based on the ParallelRunConfig configuration provided. As a model is trained for a file, its artifacts are stored in the model registry. This process is depicted in figure 2, below.

Model Scoring
A Pipeline is created and published as a PipelineEndpoint to be used for scoring models in parallel. The pipeline contains the ParallelRunStep as described above. This step executes the scoring script, which is a python script file, on each node of the Compute Cluster. Each node of the cluster takes a portion of the data to be scored and retrieves the appropriate model to use to score the new data. Finally, the scored data is stored in the Destination Reference. This process is depicted in figure 3, below.

Putting it all together
Microsoft has released the Many Models Solution Accelerator to showcase the training and scoring of hundreds of thousands of models. A deeper dive on the solution accelerator was blogged about on in the article, Train and Score Hundreds of Thousands of Models in Parallel. Finally, the product team has recorded a Many Models Solution Accelerator Video.
Comments are closed